файл robots.txt
- Што вы можаце чакаць ад гэтага артыкула У гэтым артыкуле тлумачыцца, што такое файл robots.txt і...
- Сінонімы для Robots.txt
- Чаму файл так важна robots.txt?
- Ці мае ваш robots.txt да вас?
- Robots.txt файл, ён выглядае?
- Агент карыстальніка ў robots.txt
- Disallow ў robots.txt
- дазволіць robots.txt
- Выкарыстоўвайцесімвал *
- пазначыць канец URL, выкарыстоўваючы $
- Карта сайта ў файле robots.txt
- каментары
- Абыход затрымкі ў robots.txt
- Bing, Yahoo і Яндэкс
- Baidu
- Калі мне патрэбен файл robots.txt?
- Найлепшая практыка для файла robots.txt
- прынцыпы замовы
- Толькі адна група дырэктыў робата
- Будзьце як мага больш канкрэтным
- У той жа час вызначаюць рэкамендацыі прызначаныя для ўсіх робатаў і кіраўніцтваў, прызначаных для канкрэтнага...
- Файл robots.txt для кожнага (суб) дамена.
- Супярэчлівыя рэкамендацыі: Robots.txt vs. Google Search Console
- Праверка robots.txt пасля запуску
- Не выкарыстоўвайце NoIndex ў файле robots.txt
- Прыклады файлаў robots.txt
- Усе робаты маюць доступ да ўсяго вэб-сайт
- Доступ для ўсіх робатаў
- Доступ да ўсіх робатам Google
- Доступ да ўсіх Google ботаў акрамя Googlebot Навіны
- Няма ўваходу для Googlebot і Slurp
- Няма доступу да двух каталогах для ўсіх робатаў
- Не ўдаецца атрымаць доступ да пэўнага файла для ўсіх робатаў
- Няма доступу да / адмін / Googlebot і / прыватны / для Slurp
- Robots.txt для WordPress
- Якія абмежаванні Robots.txt?
- Старонкі па-ранейшаму паказваюцца ў выніках пошуку
- кэшаванне
- файл
- FAQ Robots.txt
- 1. Ці магу я прадухіліць файл robots.txt, які паказвае старонкі ў пошукавых старонках вынікаў пошуку?
- 2. Ці ёсць у мяне быць асцярожным з файлам robots.txt?
- 3. Забаронена Ці ігнараваць файл robots.txt падчас абходу вэб-сайта?
- 4. У мяне няма файла robots.txt. Пошукавыя сістэмы скануюць мой сайт зрабіць?
- 5. Ці магу я выкарыстаць robots.txt NoIndex ў ТАГЕТ замест Disallow?
- 6. Якія пошукавыя сістэмы падтрымліваюць файл robots.txt?
- 7. Як прадухіліць пошукавыя сістэмы індэксаваць вынікі на маім сайце WordPress?
Што вы можаце чакаць ад гэтага артыкула
У гэтым артыкуле тлумачыцца, што такое файл robots.txt і як эфектыўна выкарыстоўваць яго:
- Пошукавыя сістэмы забараніць доступ да пэўных частках вашага сайта
- Для таго, каб пазбегнуць дублявання кантэнту
- Пошукавыя сістэмы, каб больш эфектыўна сканаваць ваш сайт.
Што такое файл robots.txt?
Файл robots.txt перадае правілы ўдзелу вашага сайта для пошукавых сістэм.
Перад тым, як пошукавік наведвае звычайныя старонкі на вашым сайце, то першая спроба атрымаць файл robots.txt, каб убачыць, калі ёсць спецыяльныя інструкцыі для абыходу вашага сайта. Мы называем гэтыя інструкцыі «дырэктыву».
Калі няма файла robots.txt не прысутнічае ці не адпаведных кіруючых прынцыпаў не вызначаны, то пошукавыя сістэмы будуць лічыць, што яны могуць сканаваць ўвесь сайт.
Хоць усе асноўныя пошукавыя сістэмы паважаюць рухавікі могуць па-ранейшаму ігнараваць файл robots.txt або пэўныя часткі файла robots.txt. Таму важна разумець, што ваш файл robots.txt толькі адзін набор кіруючых прынцыпаў, а не мандату.
Сінонімы для Robots.txt
Файл robots.txt таксама вядомы як Пратакол выключэння робатаў, стандарт выключэнняў для робатаў або robots.txt пратакол.
Чаму файл так важна robots.txt?
Файл robots.txt з'яўляецца вельмі важным з пошукавай аптымізацыяй (SEO) пункту гледжання. Гэта кажа пошукавым машынам, а менавіта, як лепш сканаваць ваш сайт.
З файлам robots.txt, вы можаце забараніць пошукавыя сістэмы доступу да пэўных частках вашага сайта, пазбегнуць праблем дублявання кантэнту, а таксама ў пошукавых сістэмах вызначыць , як больш эфектыўна сканаваць ваш сайт.
прыклад
Калі ласка, звярніце ўвагу на наступную сітуацыю ў якасці прыкладу:
Вам удалося сайт электроннай камерцыі, дзе наведвальнікі могуць лёгка пошук з фільтрам для прадуктаў. Гэты фільтр таксама генеруе старонкі, якія паказваюць практычна тое ж самае ўтрыманне, што і іншыя старонкі. Гэты фільтр вельмі зручна для наведвальнікаў, але збівае з толку для пошукавых сістэм, паколькі ён выклікае дубляванне кантэнту. Для прадухілення пошукавых сістэм індэксаваць гэтыя старонкі фільтруюцца, але значна лепш, каб яны не трацілі час абыходу гэтых URL-адрасоў з фільтраваныя зместам.
Акрамя таго, можна пазбегнуць праблем дублявання кантэнту кананічны URL або робатаў мета тэг, але пераканайцеся, што абедзве пошукавыя сістэмы не толькі асноўныя сканавання старонак на вашым сайце. Кананічны URL і мета - тэг робаты не перашкаджае пошукавым сістэмам старонак, але толькі гарантаваць , што пошукавыя сістэмы не адлюстроўваюць старонкі ў выніках пошуку. Так як пошукавыя сістэмы могуць вылучаць толькі абмежаваны час, каб прасканаваць сайт, вы павінны пераканацца, што пошукавыя сістэмы выдаткаваць гэты час на старонках, якія вы хочаце адлюстраваць у выніках пошуку.
Ці мае ваш robots.txt да вас?
Няправільная ўстаноўка файла robots.txt можа аказаць негатыўны ўплыў на SEO. Праверце хутка Ці гэта справа!
Robots.txt файл, ён выглядае?
Ніжэй просты прыклад таго, як файл robots.txt для WordPress можа выглядаць наступным чынам:
User-Agent: * Disallow: / WP-адміністратара /
Структура файла robots.txt вышэй выглядае наступным чынам:
Агент карыстальніка: агент карыстальніка паведамляе, якія пошукавыя сістэмы дырэктывы прызначаны.
* Гэта паказвае на тое, што рэкамендацыі прызначаныя для ўсіх пошукавых сістэм.
Disallow: Гэтая дырэктыва вызначае змесціва не даступна для агента карыстальніка.
/ Wp-адміністратар /: Гэта шлях, які не даступны для агента карыстальніка.
Кароткае апісанне: Гэты файл robots.txt паведамляе пошукавыя машыны ўсё / смецце-адмін / каталог не даступны для іх.
Агент карыстальніка ў robots.txt
Кожная пошукавая сістэма павінна вызначыць з дапамогай так званым агентам карыстальніка. робаты Google, ідэнтыфікуюць сябе ў якасці прыкладу Googlebot, Slurp і робаты, як робаты Bing ў якасці Bingbot так Yahoo.
Агент карыстальніка аб'яўляе пра пачатак шэрагу дырэктыў. У кіраўніцтве павінны быць ўстаўлена паміж першым агентам карыстальніка і наступным агентам карыстальніка, выкарыстоўваным у якасці кіраўніцтва па першым агенту карыстальніка.
Гэтыя прынцыпы могуць быць накіраваны на канкрэтныя агенты карыстальніка, але таксама могуць прымяняцца да ўсіх агентам карыстальнікаў. У апошнім выпадку мы выкарыстоўваем наступныя падстаноўныя знакі: User-Agent: *.
Disallow ў robots.txt
Вы можаце шукаць рухавікі доступ да пэўных файлаў, раздзелы або старонкі на вашым сайце забараніць дырэктыву Disallow. Пасля дырэктывы Disallow гэта шлях, які не даступны сказаў. Калі няма пэўнага шляхі не ігнараваў дырэктывы.
прыклад
User-Agent: * Disallow: / WP-адміністратара /
Прыведзены вышэй прыклад забараняе ўсе пошукавыя сістэмы доступ к / WP-адміністратар / каталогу.
дазволіць robots.txt
Дырэктыва Allow робіць процілеглы дырэктыву Disallow і падтрымліваецца Google і Bing. Рэкамендацыі Дазволіць і Забараніць выкарыстанне разам даюць пошукавым сістэмам доступ да пэўнага файла або асобным старонках у каталогу, які быў у адваротным выпадку недаступны. Пасля дырэктывы Allow гэта шлях, які даступны. Калі няма пэўнага шляхі не ігнараваў дырэктывы.
прыклад
User-Agent: * Allow: /media/terms-and-conditions.pdf Disallow: / СМІ /
Прыведзены вышэй прыклад забараняе ўсе пошукавыя сістэмы доступ к / СМІ / каталогу, за выключэннем /media/terms-and-conditions.pdf доступу да файла.
Важна: Вазьміце з выкарыстаннем Дазваляць і Disallow дырэктыў ня падстаноўныя ў файл robots.txt, таму што гэта можа выклікаць супярэчлівыя ўказанні.
Прыклад супярэчлівых кіруючых прынцыпаў
User-Agent: * Allow: / Каталог Disallow: /*.html
Пошукавыя сістэмы не ведаюць, што рабіць з URL http://www.domein.nl/directory.html ў гэтым выпадку. Гэта ясна для пошукавых сістэм, робяць яны ці не маюць доступу да гэтага URL.
Змесціце кожную дырэктыву на лінію, таму што пошукавыя сістэмы могуць у адваротным выпадку заблытацца пры аналізе файла robots.txt.
Таму пазбягайце файла robots.txt наступным чынам:
User-Agent: * Disallow: / каталог-1 / Disallow: / каталог-2 / Disallow: / каталог-3 /
Выкарыстоўвайцесімвал *
У дадатку да вызначэння агента карыстальніка, групавы сімвал таксама выкарыстоўваюцца для вызначэння URL-адрасоў, якія ўтрымліваюць пэўную радок. Падстаноўных падтрымліваецца Google, Bing, Yahoo і Ask ..
прыклад
User-Agent: * Disallow: / *?
Прыведзены вышэй прыклад забараняе ўсе пошукавыя сістэмы доступ да URL-адрасах, які змяшчае знак пытання (?).
пазначыць канец URL, выкарыстоўваючы $
Выкарыстоўвайце знак даляра ($) у канцы шляху, каб паказаць канец URL.
прыклад
User-Agent: * Disallow: /*.php$
Прыведзены вышэй прыклад забараняе ўсе пошукавыя сістэмы доступ да URL-адрасах, якія заканчваюцца на .php.
Карта сайта ў файле robots.txt
Нягледзячы на тое, што файл robots.txt ў першую чаргу прызначаны для ўказанні пошукавым сістэмам , якія старонкі яны не павінны поўзаць, ён таксама можа быць выкарыстаны для абазначэння пошукавых сістэм XML карты сайта. Гэта падтрымліваецца Google, Bing, Yahoo і Ask.
XML карта сайта павінны быць уключаны ў файл robots.txt, як абсалютны URL. URL не мае адзін і той жа хост працаваць як файл robots.txt. У якасці лепшай практыкі, мы заўсёды раім вам звярнуцца да XML Sitemap з дапамогай файлаў robots.txt, нават калі вы ўжо ўручную прадстаўлення XML карты сайта для вэб-майстроў Google Інструменты і прылады Bing для вэб-майстроў. Памятаеце, што існуюць і іншыя пошукавыя сістэмы.
Звярніце ўвагу, што можна аднесці да некалькіх XML-карта сайта ў файле robots.txt.
прыкладаў
Некалькі Sitemaps XML:
User-Agent: * Disallow: / WP-адміністратара / Карта сайта: Карта сайта https://www.voorbeeld.nl/sitemap1.xml: https://www.voorbeeld.nl/sitemap2.xml
Прыведзены вышэй прыклад забараняе ўсім пошукавым сістэмам доступ к / WP-адміністратара / і ставіцца да двух XML Sitemaps: https://www.voorbeeld.nl/sitemap1.xml
і https://www.voorbeeld.nl/sitemap2.xml.
Некаторыя XML карты сайта:
User-Agent: * Disallow: / WP-адміністратара / Карта сайта: https://www.voorbeeld.nl/sitemap_index.xml
Прыведзены вышэй прыклад забараняе ўсім пошукавым сістэмам доступ к / смецце-адмін / і ставіцца да XML-карта сайта да абсалютнага URL https://www.voorbeeld.nl/sitemap_index.xml.
каментары
Каментары з'яўляюцца пасля «#» размешчаны і могуць быць размешчаны ў пачатку новага радка або пасля дырэктывы па адной і той жа лініі. Каментары прызначаныя для выкарыстання чалавекам.
прыклад 1
# Забяспечвае доступ к / WP-адміністратара / каталог для ўсіх робатаў User-Agent: * Disallow: / WP-адміністратара /
прыклад 2
Агент карыстальніка: * #Van ставіцца да ўсіх робатам Disallow: / WP-адміністратара / не доступу / WP-адміністратара каталога / #Geeft.
Прыведзеныя вышэй прыклады звязваюцца тое ж самае.
Абыход затрымкі ў robots.txt
Дырэктыва Абыход затрымкі з'яўляецца неафіцыйным арыенцірам, які прадухіляе серверы перагружаны запытамі. Калі пошукавыя сістэмы могуць перагрузіць сервер, дадаць дырэктыву Crawl-затрымка толькі часовае рашэнне. Рэальная праблема заключаецца ў дрэннай хостынг платформы, якая працуе ваш сайт. Мы рэкамендуем, каб вырашыць гэтую праблему як мага хутчэй.
Пошукавыя сістэмы ідуць па-рознаму ў дырэктыве поўзаць затрымкі. Ніжэй мы разгадаем, як асноўныя пошукавыя сістэмы барацьбы з ім.
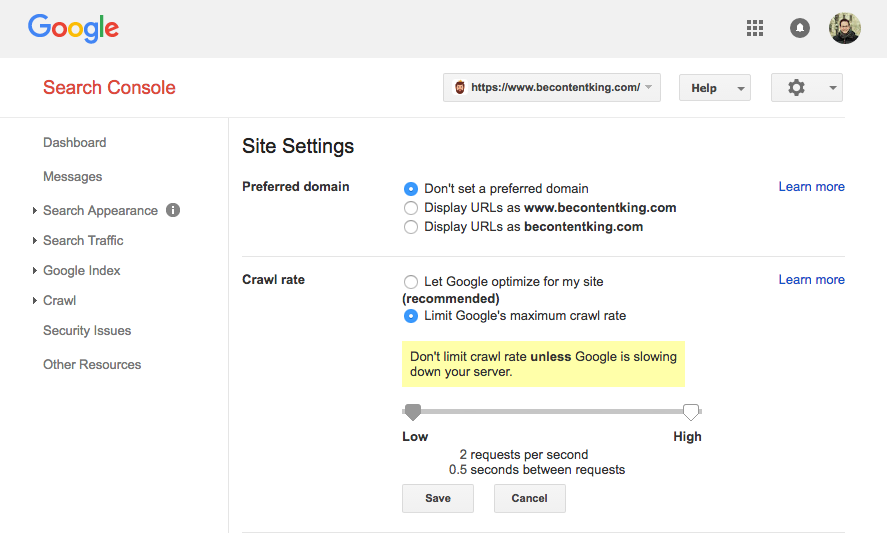
Google не падтрымлівае дырэктыву Crawl затрымкі. Тым не менш, Google мае функцыю ў Google Search Console, каб усталяваць хуткасць сканавання. Выканайце наступныя дзеянні, каб ўсталяваць хуткасць сканавання:
- Увайсці ў Google Search Console.
- Абярыце сайт, для якога вы жадаеце ўсталяваць хуткасць сканавання.
- Націсніце на значок шасцярэнькі ў правым верхнім куце і абярыце Налады сайта.
- У гэтым акне ёсць магчымасць рэгулявання гусенічнай хуткасці з дапамогай паўзунка. Хуткасць сканавання усталёўваецца як «Хай Google аптымізаваць для майго сайта (рэкамендуецца)».
Bing, Yahoo і Яндэкс
Bing, Yahoo і Яндэкс ўсе падтрымліваюць Crawl затрымкі дырэктывы налады максімальнай хуткасці сканавання (глядзіце дакументацыю для Bing, Yahoo, Yandex). Змесціце дырэктыву Crawl затрымкі адразу пасля Disallow або Дазволіць дырэктывы.
прыклад:
Агент карыстальніка: Bingbot Disallow: / прыватны / Crawl затрымкі: 10
Baidu
Baidu падтрымлівае дырэктыву Crawl затрымкі няма. Тым не менш, можна рэгуляваць хуткасць сканавання ў вашым Webmaster Tools кошт Baidu. Гэта працуе так жа, як і ў Google Search Console.
Калі мне патрэбен файл robots.txt?
Мы рэкамендуем заўсёды выкарыстоўваць файл robots.txt. Даданне файла robots.txt на ваш сайт не мае адваротны бок, і гэта эфектыўны спосаб зносін інструкцыі для пошукавых сістэм, як лепш сканаваць ваш сайт.
Найлепшая практыка для файла robots.txt
Змесціце файл robots.txt заўсёды знаходзіцца ў каранёвым каталогу вашага сайта (самы высокі каталог хаста) і даць яму файл robots.txt, напрыклад: https://www.voorbeeld.nl/robots.txt. URL для файла robots.txt, як і любога іншага URL адчувальныя да рэгістра.
Калі пошукавыя сістэмы не могуць знайсці файл robots.txt ў тэчцы па змаўчанні, яны мяркуюць, што няма ніякіх кіруючых прынцыпаў, каб прасканаваць ваш сайт і скануюць іх усе.
прынцыпы замовы
Важна ведаць, што пошукавыя сістэмы ўсе здзелкі з файлам robots.txt. Стандарт выйграў першую агульную дырэктыву.
Тым ня менш, Google і Bing глядзець на спецыфічнасці. Прыклад: Дазволіць richtlin выйграе дырэктыву Disallow як колькасць сімвалаў больш.
прыклад
User-Agent: * Allow: / а / кампаніі / Disallow: / а /
Прыведзеная вышэй прыклад забараняе ўсе пошукавыя сістэмы, у тым ліку Google і Bing, доступ к / п / дырэкторыі, у дадатку да паддырэкторыі / о / кампаніі /.
прыклад
User-Agent: * Disallow: / аб / Allow: / а / кампаніі /
Прыведзены вышэй прыклад выключае ўсе рухавікі, акрамя Google і Bing доступу к / п / дырэкторыі, уключаючы / аб / кампаніі /.
Google і Bing маюць доступ, таму што дырэктыва Allow перавышае дырэктыву Disallow.
Толькі адна група дырэктыў робата
Вы можаце вызначыць толькі адну групу згодна з патрабаваннямі пошукавых сістэм. Ўключэнне некалькіх груп дырэктыў у файле robots.txt блытаць пошукавыя сістэмы.
Будзьце як мага больш канкрэтным
Дырэктыва Disallow таксама працуе для частковага супадзення. Будзьце як мага больш канкрэтнымі ў вызначэнні дырэктывы Disallow, каб прадухіліць вас ад ненаўмысных забараніць пошукавыя сістэмы доступу да файлаў.
прыклад
User-Agent: * Disallow: / Каталог
Прыклад забараняе пошукавым сістэмам доступ да вышэй:
/ Каталог /
/ Даведнік-імя-1
/directory-name.html
/directory-name.php
/directory-name.pdf
У той жа час вызначаюць рэкамендацыі прызначаныя для ўсіх робатаў і кіраўніцтваў, прызначаных для канкрэтнага робата
Як кіруючыя прынцыпы для ўсіх робатаў варта кіруючым прынцыпы для канкрэтнага робата, былыя дырэктывы ігнаруюцца канкрэтна згаданы робатам. Адзіны спосаб кантраляваць робат канкрэтна згаданы кіруючыя прынцыпы для ўсіх робатаў, вызначыўшы яго зноў для канкрэтнага робата.
Давайце паглядзім на прыклад, які робіць гэта ясна:
прыклад
User-Agent: * Disallow: / таямніца / Disallow: / пакуль яшчэ не запушчаны / User-Agent: Googlebot Disallow: / пакуль яшчэ не запушчаны /
Прыведзены вышэй прыклад выключае ўсе рухавікі , акрамя Google доступу / сакрэце / і / пакуль яшчэ не запушчаны /. Гэты файл robots.txt, Google не толькі маюць доступ да / пакуль яшчэ не запушчаны /, а проста доступ / сакрэтны /.
Калі вы не хочаце Googlebot доступ к / сакрэце / або / пакуль яшчэ не запушчаны /, затым паўтарыце рэкамендацыі па Googlebot:
User-Agent: * Disallow: / таямніца / Disallow: / пакуль яшчэ не запушчаны / User-Agent: Googlebot Disallow: / Сакрэт / Disallow: / пакуль яшчэ не запушчаны /
Файл robots.txt для кожнага (суб) дамена.
Дырэктывы ў файле robots.txt прымяняюцца толькi да хасту, дзе размешчаны файл.
прыкладаў
http://example.com/robots.txt прымяняе http://example.com, але не http://www.voorbeeld.nl або https://voorbeeld.nl.
Супярэчлівыя рэкамендацыі: Robots.txt vs. Google Search Console
Калі правілы ў файле robots.txt канфлікту з наладамі, якія вы вызначылі ў Google Webmaster Tools ,, Google выбірае, у многіх выпадках для налады, якія вы вызначылі ў Google Search Console замест дырэктыў у файле robots.txt файл.
Праверка robots.txt пасля запуску
Праверка пасля запуску новых функцый або новы вэб-сайт з тэставай асяроддзя ў вытворчай асяроддзі заўсёды файл robots.txt для Disallow /.
Не выкарыстоўвайце NoIndex ў файле robots.txt
Хоць некаторыя рэкамендуюць выкарыстоўваць NoIndex дырэктывы ў файле robots.txt, гэта не з'яўляецца афіцыйным стандарт. Акрамя таго, Google публічна заявіў, не выкарыстоўваць яго. Не зразумела чаму, але мы рэкамендуем прыняць іх рэкамендацыі сур'ёзна.
Прыклады файлаў robots.txt
У гэтай частцы мы прывядзем некаторыя прыклады файлаў robots.txt.
Усе робаты маюць доступ да ўсяго вэб-сайт
Ёсць некалькі спосабаў паведаміць пошукавым сістэмам, што яны маюць доступ да ўсяго сайту:
User-Agent: * Disallow:
або
Маючы пусты файл robots.txt на ўсіх ці не файла robots.txt.
Доступ для ўсіх робатаў
User-Agent: * Disallow: /
Pro савет: дадатковы персанаж можа зрабіць розніцу.
Доступ да ўсіх робатам Google
User-Agent: Googlebot Disallow: /
Звярніце ўвагу, што калі вы не дазваляеце Googlebot, гэта ставіцца да ўсіх робатам Google. Так што робаты Google, якія шукаюць, напрыклад навіны (Googlebot-News) або малюнка (Googlebot-малюнкі).
Доступ да ўсіх Google ботаў акрамя Googlebot Навіны
User-Agent: Googlebot Disallow: / User-Agent: Googlebot-News Disallow:
Няма ўваходу для Googlebot і Slurp
Агент карыстальніка: Slurp User-Agent: Googlebot Disallow: /
Няма доступу да двух каталогах для ўсіх робатаў
User-Agent: * Disallow: / адміністратар / Disallow: / прыватных /
Не ўдаецца атрымаць доступ да пэўнага файла для ўсіх робатаў
User-Agent: * Disallow: /directory/some-pdf.pdf
Няма доступу да / адмін / Googlebot і / прыватны / для Slurp
User-Agent: Googlebot Disallow: / адміністратар / User-агент: Slurp Disallow: / прыватны /
Robots.txt для WordPress
Файл robots.txt ніжэй аптымізаваны для WordPress, мяркуючы, што:
- Ваш адмін падзел не хоча шукальнікам.
- Ваш ўнутраны пошук старонак вынікаў не хочуць поўзаць на вашым сайце.
- Пазначыўшы і аўтар старонкі архіва не хочуць шукальнікам.
- Вы не хочаце, каб сканаваць старонку 404.
User-Agent: * Disallow: / WP-адміністратара / доступ адміністратара #geen падзел. Disallow: /wp-login.php#geen доступ да адмін секцыі. Disallow: / пошук / #geen zoekresutlaat доступ да унутраным старонках. Disallow: * S = * доступ да унутраным старонках zoekresutlaat?. Disallow: * р = * #geen доступ да старонак як пастаянныя спасылкі не працуюць?. Disallow: * & р = * ня атрымаць доступ да старонак, як Permalinks не працуюць. Disallow: * = * & Папярэдні прагляд #geen доступ да папярэдняй прагляду старонках. Disallow: / тэгі / #geen доступу пазначаць старонкі архіва Disallow: / аўтар / #geen доступ да архіўнага аўтару старонках. Disallow: / 404 памылка доступу / #geen 404 старонак. Карта сайта: https://www.voorbeeld.nl/sitemap_index.xml
Nota Bene: гэта robots.txt працуе ў большасці выпадкаў. Тым ня менш, пераканайцеся , што вы заўсёды можаце наладзіць і прымяніць да вашай канкрэтнай сітуацыі.
Якія абмежаванні Robots.txt?
Файл robots.txt ўтрымлівае дырэктывы
Нягледзячы на тое, што файл robots.txt добра паважаў пошукавыя сістэмы, яна застаецца арыенцірам, а не мандат.
Старонкі па-ранейшаму паказваюцца ў выніках пошуку
Старонкі, якія не даступныя для пошукавых сістэм у файле robots.txt, па-ранейшаму могуць з'яўляцца ў выніках пошуку, калі яны звязаны з старонкі будуць праглядацца. Гэта выглядае наступным чынам:

Protip: Ці можна выдаліць гэтыя адрасы з вынікаў пошуку з інструментам для выдалення URL Google вэб - майстроў. Памятаеце, што Google толькі часова выдаліць гэтыя URL-адрасы. Выдаліць URL ўручную кожныя 90 дзён, каб прадухіліць іх з'яўленне ў выніках пошуку.
кэшаванне
Google заявіў, што звычайна 24 гадзіны ў кэшы файл robots.txt. Майце гэта на ўвазе, калі вы ўносіце змены ў файл robots.txt.
Пакуль незразумела, як іншыя пошукавыя сістэмы апрацоўваць кэшаванне файлаў robots.txt.
файл
Google у цяперашні час падтрымлівае максімальны памер файла 500 кб для файлаў robots.txt. Усе ўтрыманне можа быць праігнаравана пасля гэтага максімуму.
Няясна, ці будзе выкарыстоўваць іншыя пошукавыя сістэмы максімальны памер файла.
FAQ Robots.txt
- Ці магу я прадухіліць файл robots.txt, які паказвае старонкі ў пошукавых старонках вынікаў пошуку?
- Я павінен быць асцярожным з файлам robots.txt?
- Гэта незаконна, каб ігнараваць файл robots.txt падчас абходу вэб-сайта?
- У мяне няма файла robots.txt. Пошукавыя сістэмы скануюць мой сайт зрабіць?
- Ці магу я выкарыстаць robots.txt NoIndex ў ТАГЕТ замест Disallow?
- Якія пошукавыя рухавічкі падтрымліваюць файл robots.txt?
- Як прадухіліць пошукавыя сістэмы індэксаваць вынікі на маім сайце WordPress?
1. Ці магу я прадухіліць файл robots.txt, які паказвае старонкі ў пошукавых старонках вынікаў пошуку?
Не, гэта адбываецца, як паказана:
Акрамя таго: Калі Google не мае доступу ўтрымлівае старонкі з дапамогай файлаў robots.txt і саму старонку а <META NAME = «робаты» змест = «NOINDEX, NOFOLLOW»> тэг, то пошукавыя сістэмы будуць па-ранейшаму індэксаваць старонку. Г.зн. яны не ведаюць пра <META NAME = «робаты» змест = «NOINDEX, NOFOLLOW»> таму, што ў іх няма доступу да гэтай старонцы.
2. Ці ёсць у мяне быць асцярожным з файлам robots.txt?
Так, але не бойцеся выкарыстоўваць. Гэта выдатны інструмент для лепш сканаваць ваш сайт з дапамогай Google.
3. Забаронена Ці ігнараваць файл robots.txt падчас абходу вэб-сайта?
У тэорыі. Файл robots.txt з'яўляецца дадатковым арыенцірам для пошукавых сістэм. З юрыдычнага пункту гледжання, мы можам аднак сказаць што-небудзь пра гэта. Калі вы сумняваецеся, атрымаць кансультацыю ў юрыста.
4. У мяне няма файла robots.txt. Пошукавыя сістэмы скануюць мой сайт зрабіць?
Так. Калі пошукавыя машыны знаходзяць яны лічаць, што няма ніякіх кіруючых прынцыпаў не з'яўляецца файл robots.txt, і яны скануюць ўвесь сайт.
5. Ці магу я выкарыстаць robots.txt NoIndex ў ТАГЕТ замест Disallow?
Не, гэта не рэкамендуецца. Google рэкамендуе гэты канкрэтны оф ,
6. Якія пошукавыя сістэмы падтрымліваюць файл robots.txt?
Усе асноўныя пошукавыя сістэмы падтрымліваюць файл robots.txt:
7. Як прадухіліць пошукавыя сістэмы індэксаваць вынікі на маім сайце WordPress?
Разгледзім наступныя правілы ў файле robots.txt. Гэта прадухіляе пошукавыя сістэмы індэксаваць гэтыя старонкі, мяркуючы, што няма ніякіх зменаў у функцыянаванні на старонках вынікаў пошуку.
User-Agent: * Disallow: / с = Disallow: / пошук /
Больш падрабязна аб файле robots.txt:
Txt?Txt да вас?
Txt файл, ён выглядае?
Txt?
Txt?
Txt, які паказвае старонкі ў пошукавых старонках вынікаў пошуку?
Txt?
Txt падчас абходу вэб-сайта?
Пошукавыя сістэмы скануюць мой сайт зрабіць?
Txt NoIndex ў ТАГЕТ замест Disallow?